使用neo4j数据库管理用户关系
引言
再做一些涉及到数据深度关系的管理时,传统的关系型数据库,如Mysql、Oracle就显得不那么方便了。例如一个邀请功能,A邀请了B,B邀请了C,C邀请了D,如何快速的查出D是A的第三代下家?用传统数据库,不是在查询的时候费事费劲,就是在插入的时候要想方设法。
不仅是上述的场景,还有很多,比如常见的好友推荐,推特上常能看见的好友的喜欢等等。传统数据库肯定无法支撑,所以采用了一种NOSQL,图数据库,今天要介绍的neo4j也是图数据库中的老大。
安装
下载地址
打开官网下载,可以下载Server版,也可以下载Desktop版,桌面版能更轻松友好的管理你的数据库,下面介绍桌面版的安装。
下载完毕后打开,点击New可以新建一个工程
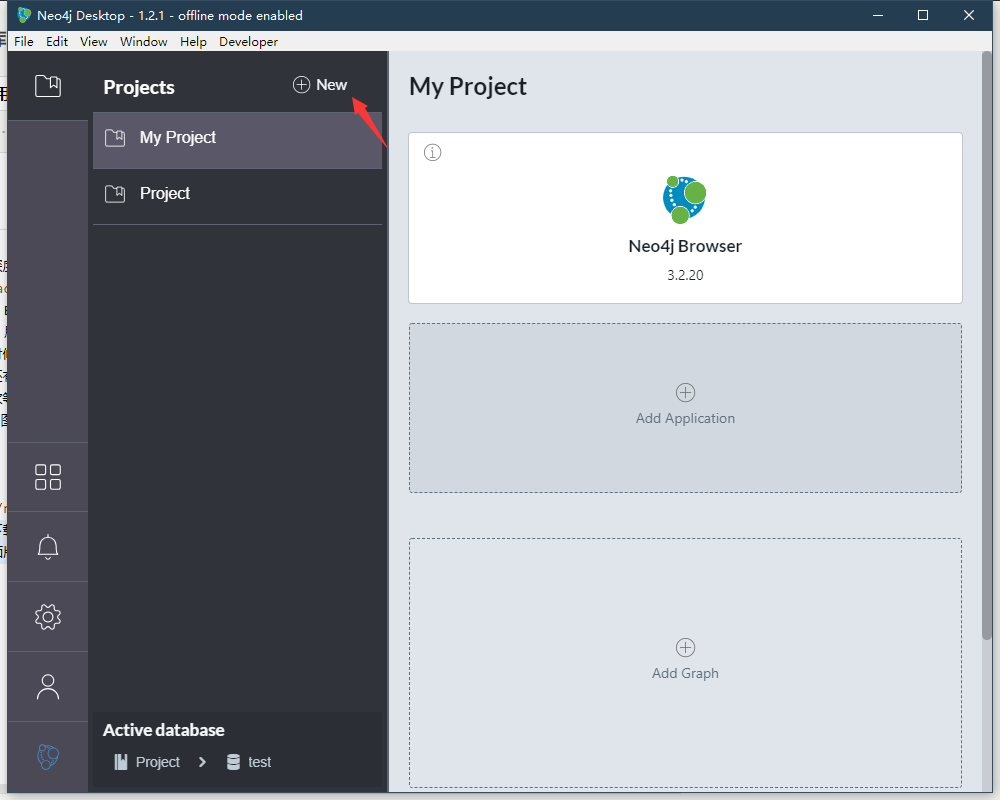
点击Add Graph创建一个图数据库
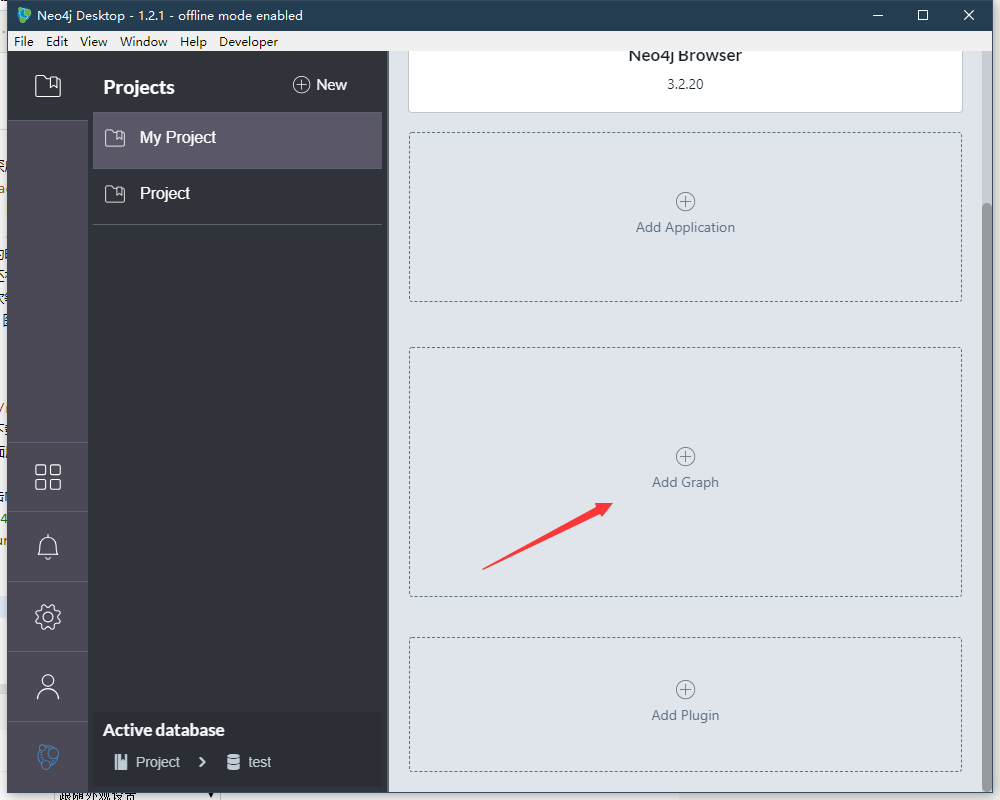
可以选择创建一个本地数据库还是连接一个服务器端的数据库
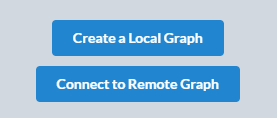
创建完毕后点击Manage可以进行端口设置等,点击Start启动数据库,启动完成后点击上方的Neo4j Browser打开数据库管理界面
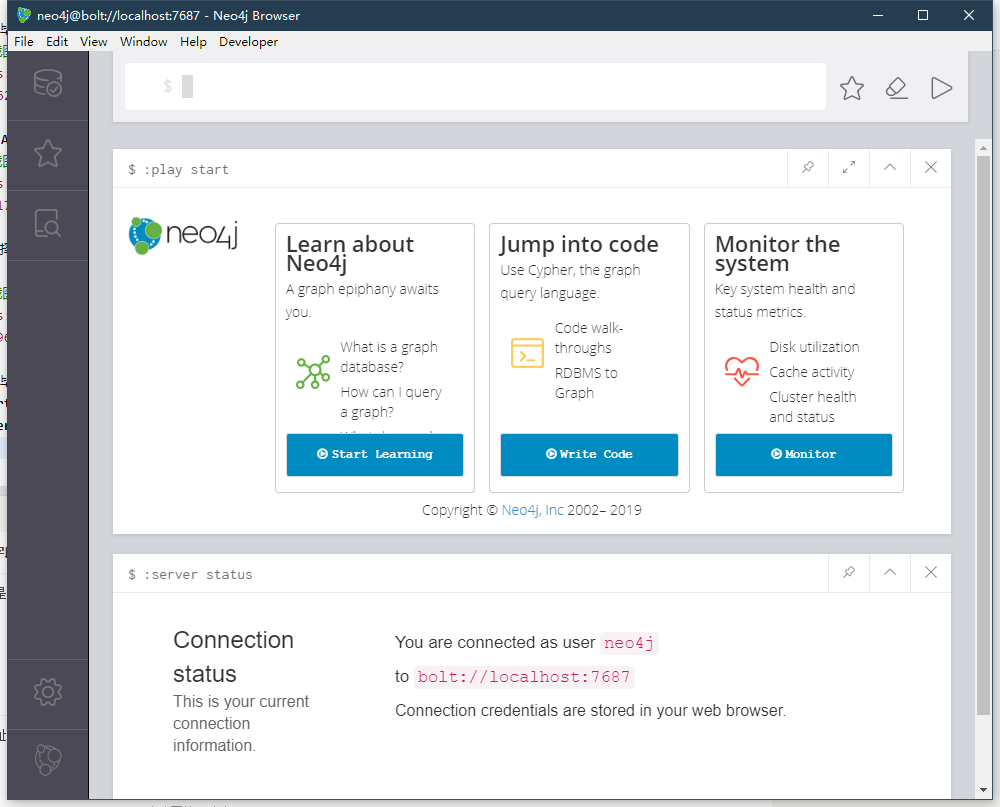
到这步为止已经算安装好了neo4j数据库
基本语法
neo4j的语法与一般SQL不一样,使用的是CQL,下面介绍一下基本的语法。
CREATE
数据库无非增删改查,先从增说起。
CREATE
(
<node-name>:<label-name>
)
我现在要创建一个学生,我可以使用
CREATE (stu:Student)
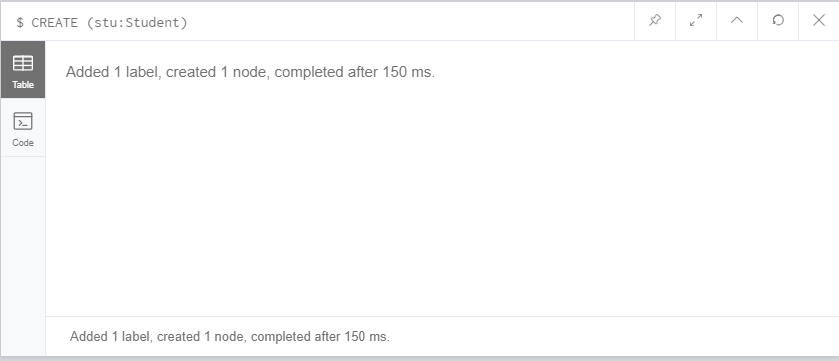
上面的语句中,我们创建了一个带有Student标签的节点(Node),而stu可以看作这个节点的“实例化对象”而并非这个节点的名字,有什么用呢?看下面的语句。
CREATE (stu:Student) RETURN stu
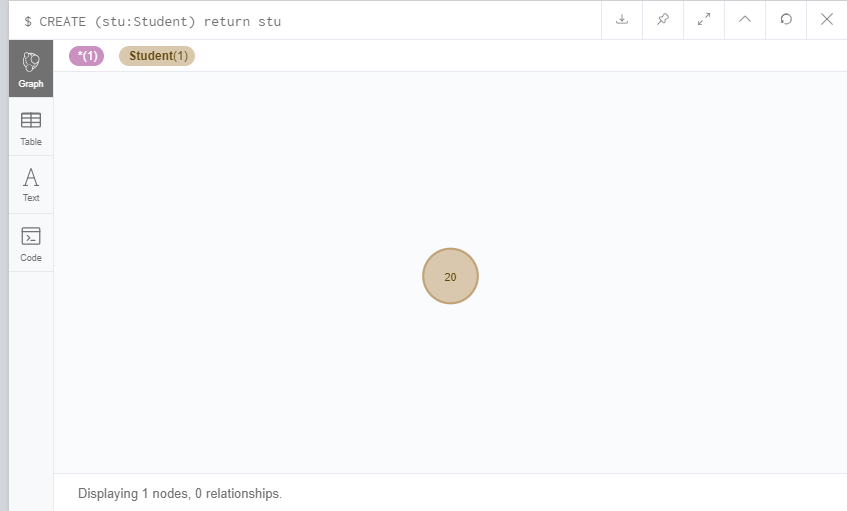
我们又创建了一个Student的节点stu,不同的是我们用了RETURN语句返回了stu。是不是能理解了,上面的语句就是创建一个节点并返回这个节点。如果只是单纯的创建一个节点不用返回,可以不用写<node-name>,直接
CREATE (:Student)
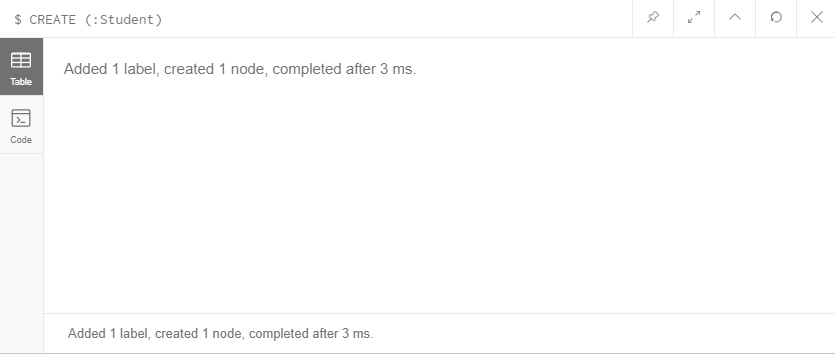
节点可以有自己的属性
CREATE (
<node-name>:<label-name>
{
<Property1-name>:<Property1-Value>
........
<Propertyn-name>:<Propertyn-Value>
}
)
属性用键值对表示,字符串需要用单引号引起来
CREATE (stu:Student{id:1,name:'Alex'}) RETURN stu
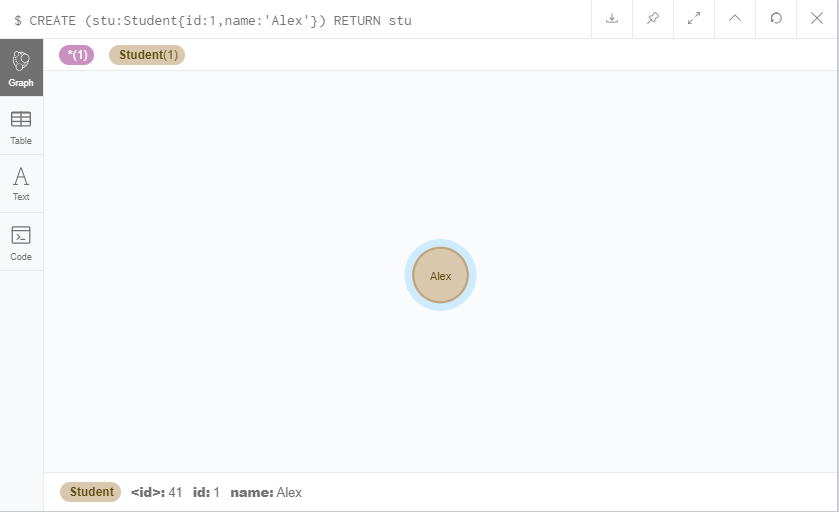
<id>是数据库维护的节点id,跟我们的业务无关。
MATCH
MATCH
(
<node-name>:<label-name>
)
我们想查出来刚才创建的一堆Student节点的话
MATCH (stu:Student) RETURN stu
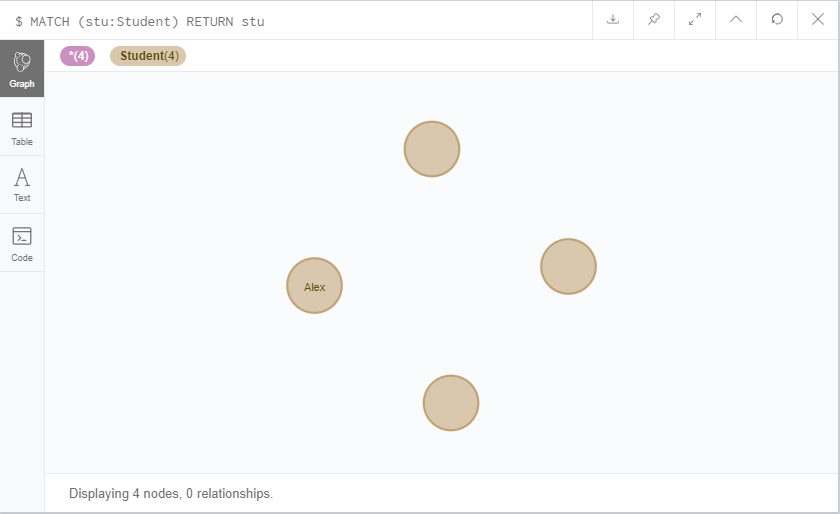
这就是我们刚才创建的那一堆节点。需要注意的是,MATCH必须和RETURN一起使用。
如果想要带条件查询,比如查询名为Alex的学生
MATCH (stu:Student{name:'Alex'}) RETURN stu
MATCH (stu:Student) WHERE stu.name='Alex' RETURN stu
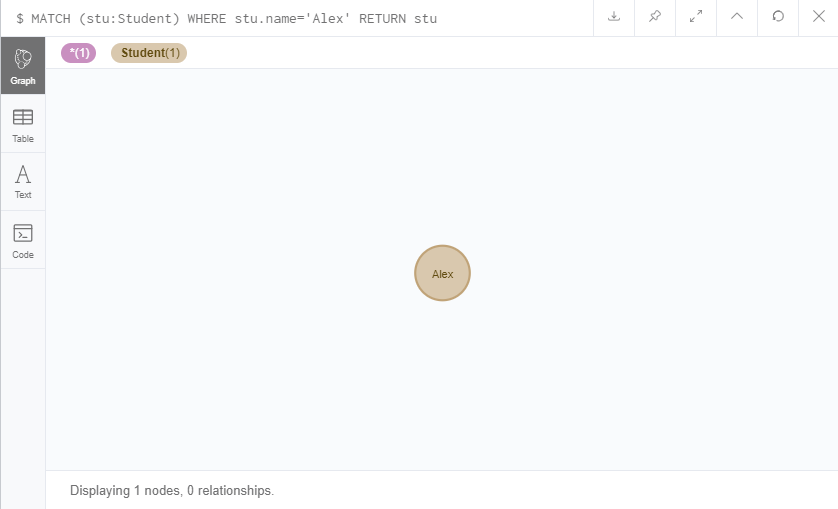
直接在节点标签后跟上属性或者用熟悉的WHERE都可以查询。
MERGE
MERGE语法跟CREATE大相径庭,使用CREATE的话总是会创建一个新的节点,使用MERGE的话会判断是否有相同属性的节点,如果没有则创建,有则不做任何操作。
MERGE (stu:Student{id:1,name:'Alex'}) RETURN stu
MATCH (stu:Student) RETURN stu
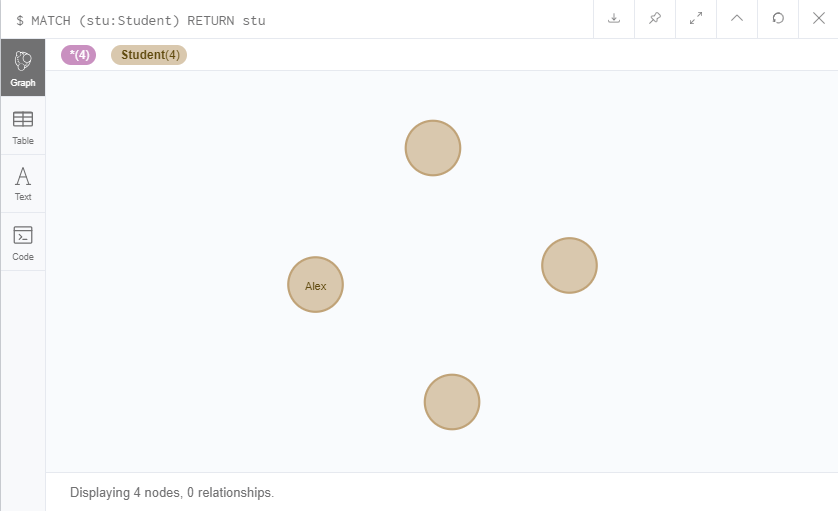
仍然只有一个名为Alex的学生。
如果MERGE一个没有属性的节点的话,则会判断有没有该标签的节点,没有则创建,有则略过。
MERGE (stu:Student) RETURN stu
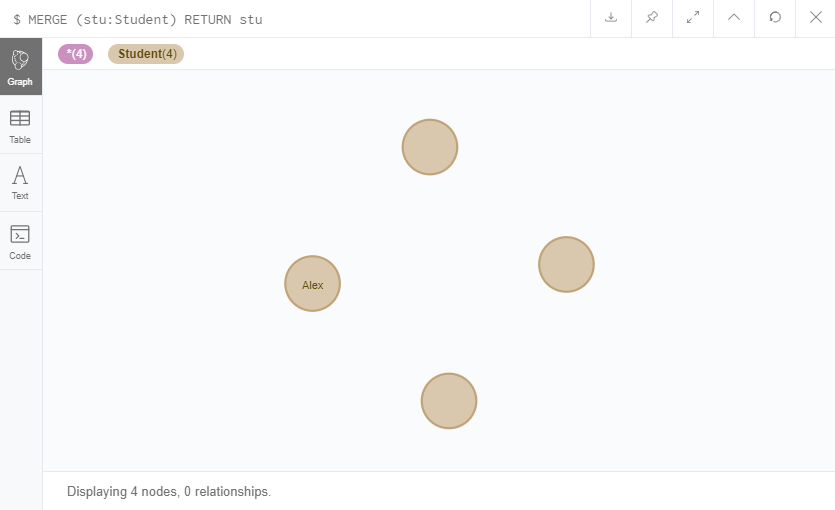
SET
增和查介绍了,再介绍一下改了。
SET和REMOVE两个关键字可以增加、更改和删除节点的属性。
MATCH (stu:Student{id:1})
SET stu.sex='man'
SET stu.name='Nick'
RETURN stu
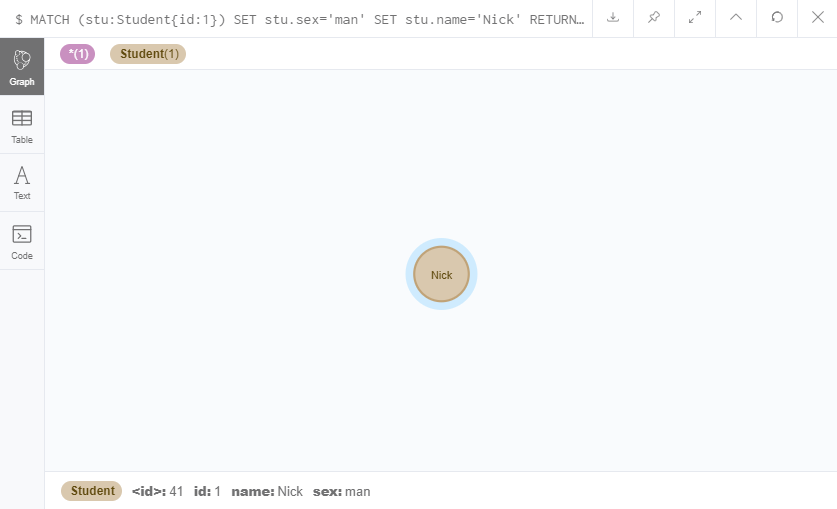
上面的语句中我们查到了id为1的Student并添加了新属性sex,改变了name。
MATCH (stu:Student{id:1})
REMOVE stu.name
RETURN stu
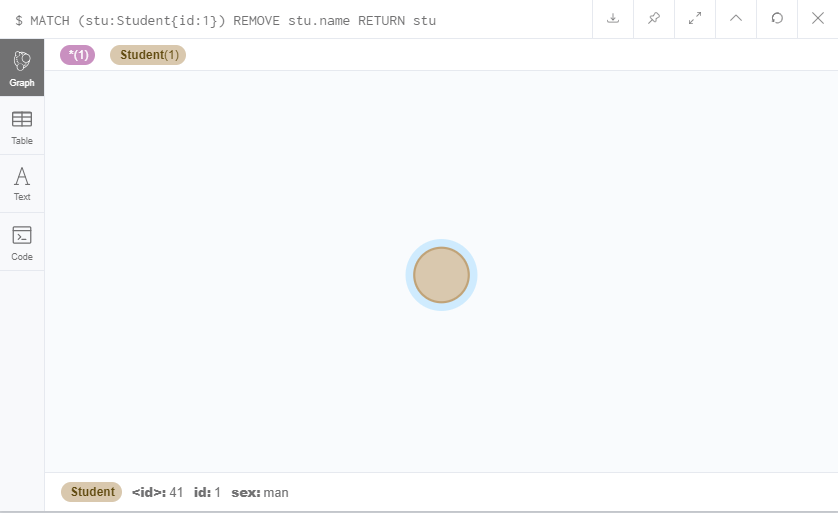
可以看到,这个Student节点的name已经被我们删掉了。
DELETE
DELETE <node-name-list>
删除MATCH得到的所有节点。
MATCH (stu:Student) DELETE stu
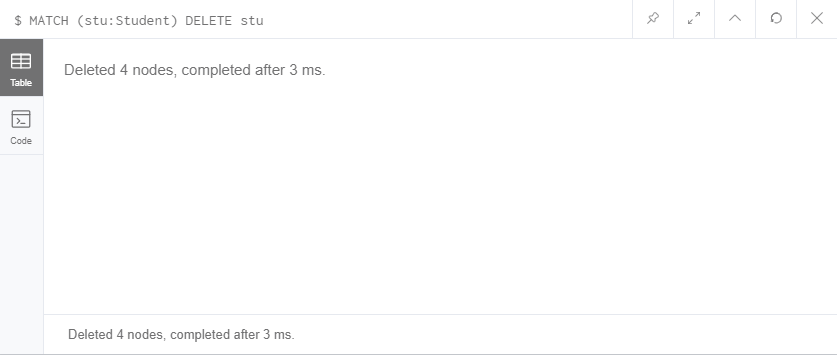
现在所有的学生都被我们删除了。
关系
neo4j数据库中主要存储着两类东西,节点和关系。节点上面已经介绍了,下面介绍节点之间的关系。
创建关系
CREATE
(
<node1-name>)-[<relationship-name>:<relationship-lable>]->(<node2-name>
)
注意箭头的指向,node1指向了node2,代表node1对node2发起了关系。
我们先创建一名学生和一名老师
CREATE (:Student{id:1,name:'Alex'})
CREATE (:Teacher{id:1,name:'Tom'})
然后给他们添加关系
MATCH (stu:Student{id:1}),(tea:Teacher{id:1})
CREATE (tea)-[r:Teach]->(stu)
RETURN tea,r,stu
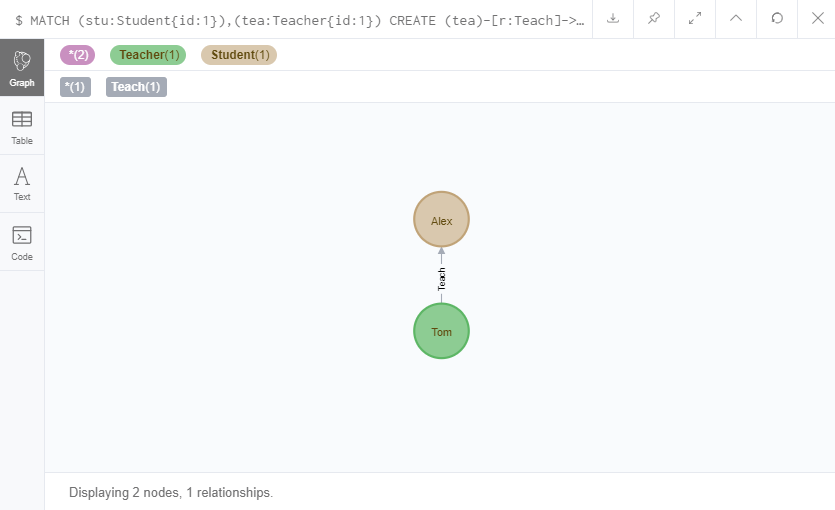
这样就建立起了一个师生关系。
上面的语句可以用MERGE替换一下
MERGE (stu:Student{id:1})-[r:Teach]->(tea:Teacher{id:1})
RETURN tea,r,stu
如果这样写的话,没有id为1的学生或者没有id为1的老师,都会自动创建新节点,但是新节点没有name属性。所以根据业务逻辑自行判断语句怎么写。
MATCH (tea:Teacher{id:1})
MERGE (tea)-[r:Teach]->(stu:Student{id:2,name:'Bob'})
RETURN tea,r,stu
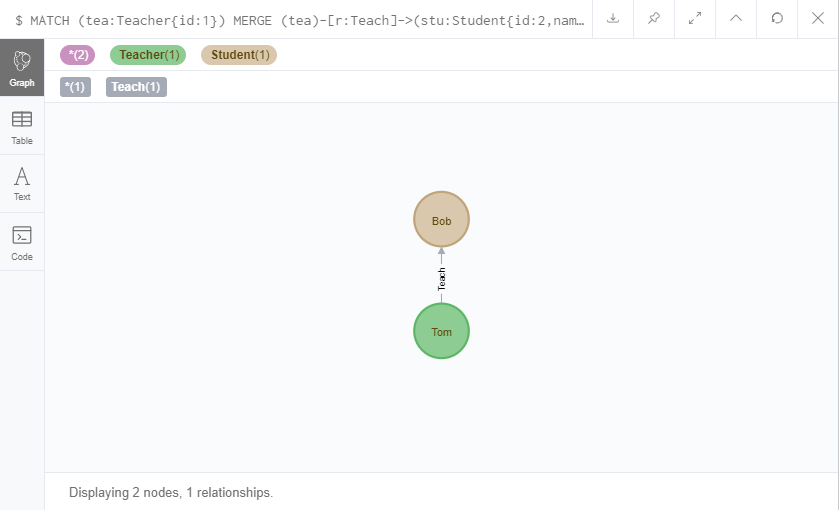
上面的语句我直接创建了一个新学生Bob,并直接与现有老师Tom建立了师生关系。
查询关系
MATCH
(
<node1-name>:<label-name>
)
- [<relationship-name>:<relationship-lable>] ->
(
<node2-name>:<label-name>
)
这里还是要注意箭头方向,你也可以把箭头反着写
<- [<relationship-name>:<relationship-lable>] -
还可以不写箭头,查询的时候就会忽略关系的发起方向,只要存在关系即可,适用于好友关系之类的。
- [<relationship-name>:<relationship-lable>] -
MATCH (tea:Teacher) -[r:Teach]-> (stu:Student) RETURN stu,r,tea
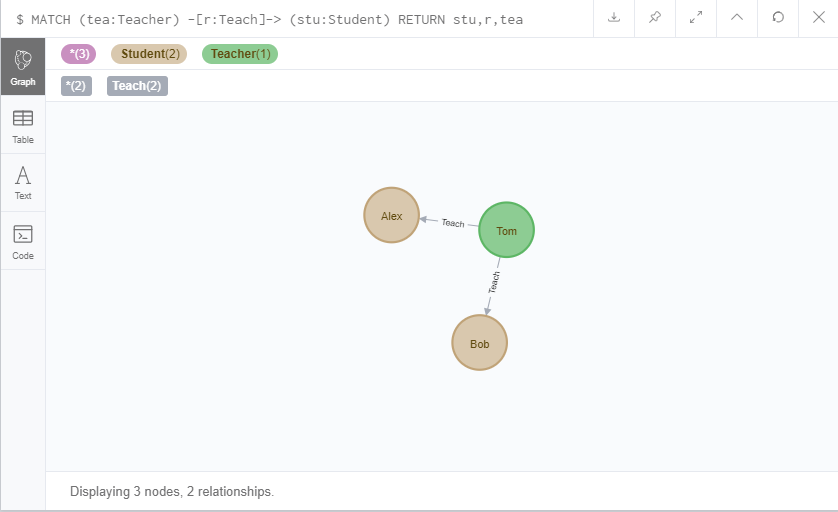
上面语句我查询了所有有师生关系的老师和学生。
关系属性
关系也是可以拥有属性的。
MATCH (tea:Teacher{id:1})
MERGE (tea)-[r:Teach{startTime:1564819664}]->(stu:Student{id:3,name:'Ana'})
RETURN tea,r,stu
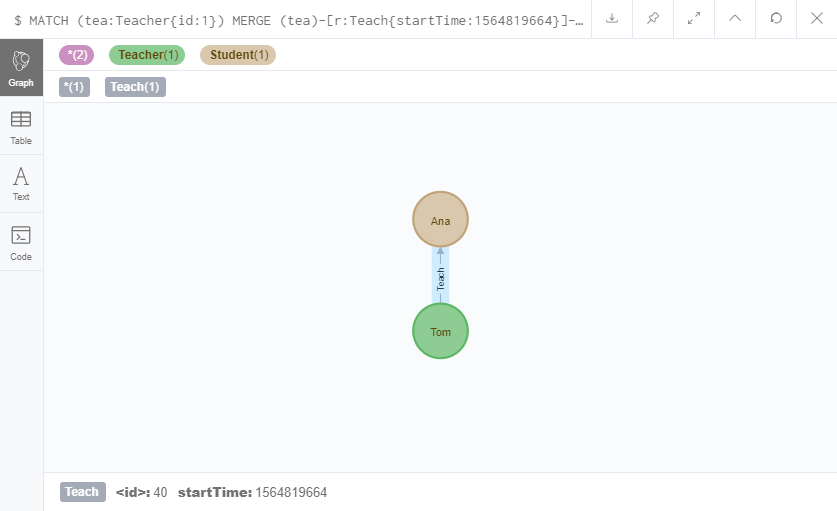
我又给Tom老师添加了一个学生Ana,并且在关系上还注明了开始时间startTime。
SET和REMOVE同样适用于关系的属性
MATCH (tea:Teacher) - [r:Teach] -> (stu:Student)
WHERE r.startTime IS NULL
SET r.startTime = 1564820027
RETURN tea,r,stu
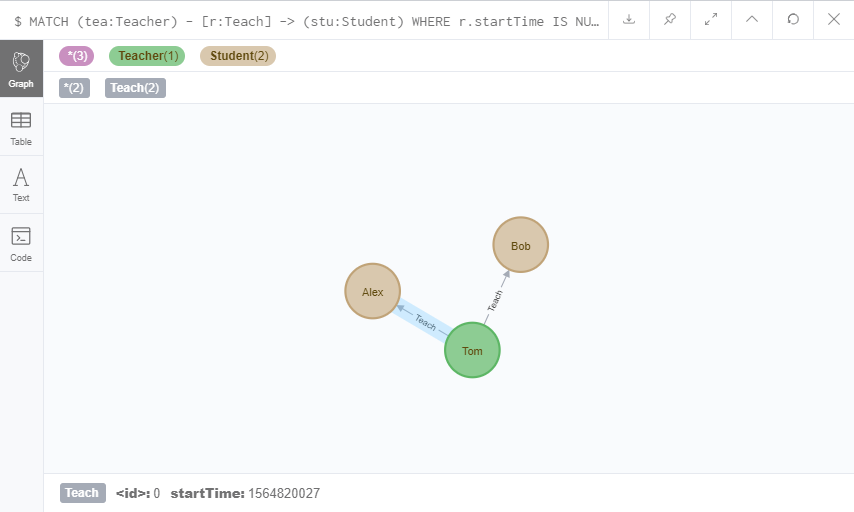
我给所有没有startTime属性的Teach关系都添加了startTime属性。注意,属性没有定义的时候为NULL,需要用IS关键字判断。
删除关系
DELETE <relationship-name-list>
MATCH (tea:Teacher{id:1}) - [r:Teach] -> (stu:Student{name:'Alex'})
DELETE r
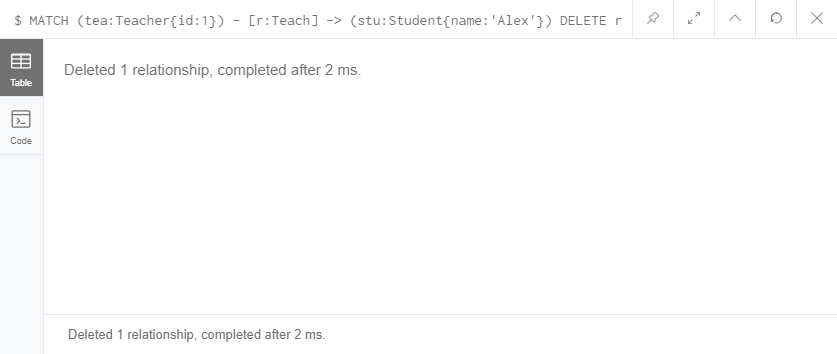
跟删除节点一样,上面的语句我删除了Alex和Tom老师的师生关系。
层级关系
下面说一些多级关系的简单处理操作。
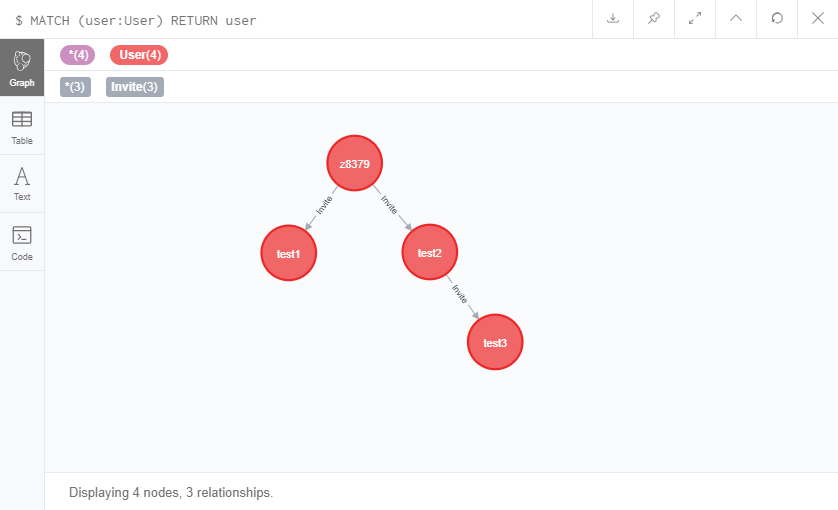
这是我已经建立好的一个邀请关系图。
查看一级下家的话很简单
MATCH (p:User{userAccount:'z8379'}) - [:Invite] -> (s:User)
RETURN p,s
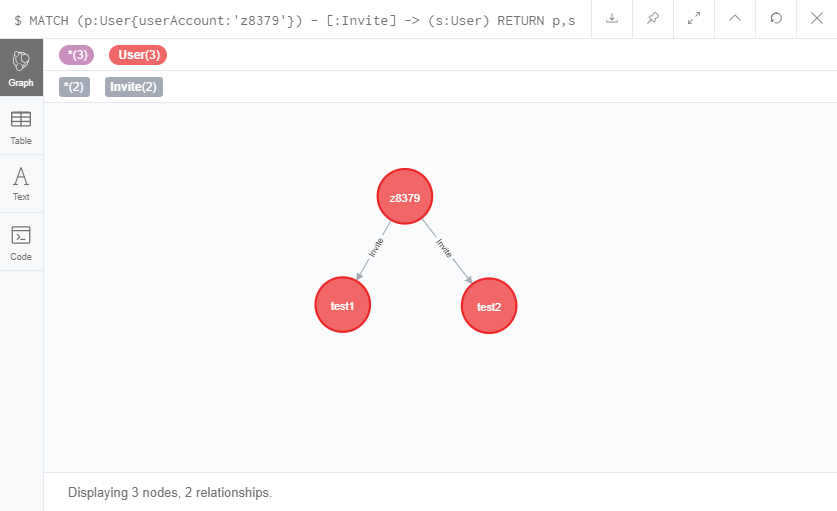
如果要查看我的所有二级下家的话
MATCH (p:User{userAccount:'z8379'}) - [:Invite*2] -> (s:User)
RETURN p,s
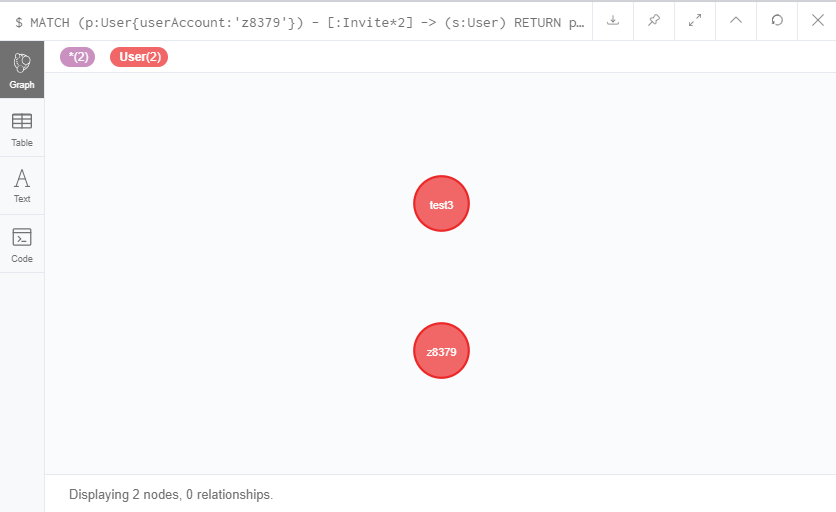
在<relationship-lable>后加上了*2,代表着2层Invite关系。
还可以使用*1..3代表1-3层的关系,*2..代表2层往后的所有关系。
MATCH (p:User{userAccount:'z8379'}) - [:Invite*1..] -> (s:User)
RETURN p,s
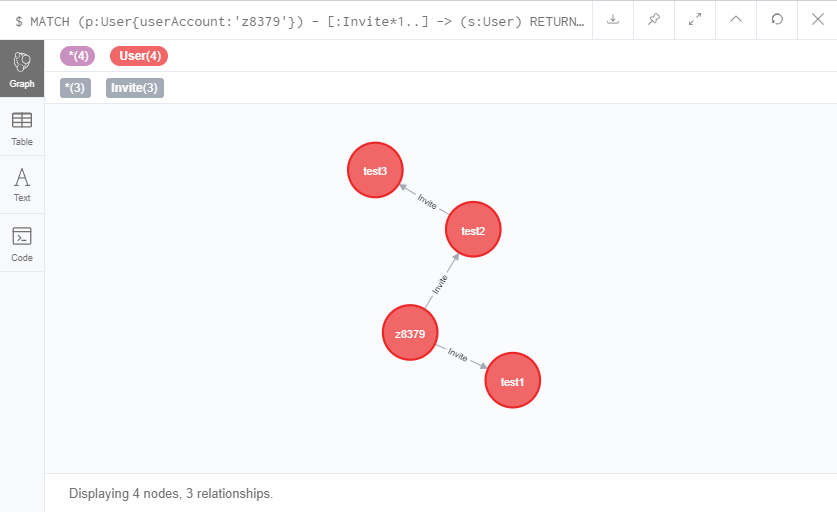
我用上面的一条语句就能查出我的所有的下家,以及下家的下家,下家的下家的下家。。。
Java应用
Java连接neo4j有两种方式,一种是嵌入式,一种是服务器模式,因为neo4j也是用java开发的,使用嵌入式也就是让他们共用一个jvm,能在一定程度上提升性能,但是如果涉及到分布式存储的话,那就只能采取服务器模式了,本文也只介绍服务器模式
Maven包
<dependency>
<groupId>org.neo4j.driver</groupId>
<artifactId>neo4j-java-driver</artifactId>
<version>1.5.0</version>
</dependency>
封装方法
import com.rome.common.utils.init.Initer;
import io.vertx.core.json.JsonObject;
import org.neo4j.driver.v1.AuthTokens;
import org.neo4j.driver.v1.Driver;
import org.neo4j.driver.v1.GraphDatabase;
import org.neo4j.driver.v1.Session;
/**
* @author z8379
*/
public class Neo4jUtil {
private static Session session = null;
public static Session getClient() {
if (session == null) {
JsonObject config = Initer.getConfig("neo4j");
Driver driver = GraphDatabase.driver(config.getString("url"),
AuthTokens.basic(config.getString("username"), config.getString("password")));
session = driver.session();
}
return session;
}
}
执行语句
StatementResult result = neo4jClient.run(
"match (p:User{userAccount:{userAccount}})-[r:Invite]->(s:User) return p,s,r",
parameters("userAccount", userAccount));
while (result.hasNext()) {
Record record = result.next();
Node inviter = record.get("s").asNode();
Relationship relationship = record.get("r").asRelationship();
HashMap<String, Object> map = new HashMap<String, Object>(2);
map.put("userAccount", inviter.asMap().get("userAccount"));
map.put("createTime", relationship.asMap().get("createTime"));
list.add(map);
}
上面的操作是取userAccount的所有一级下家。
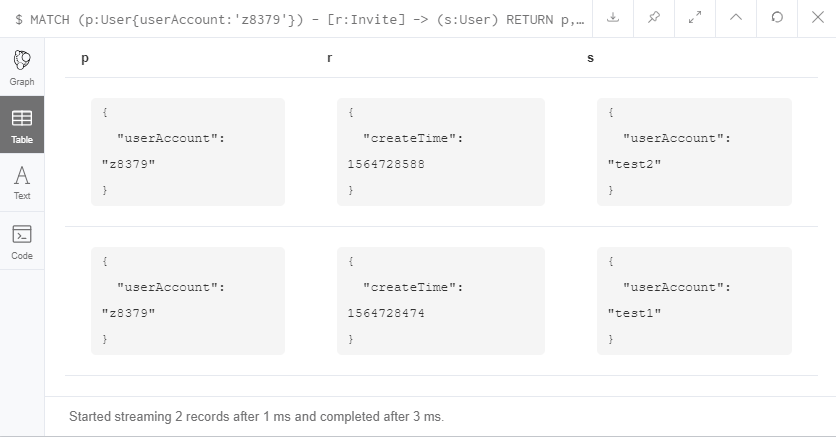
返回的结果集长这样的。两行数据在result中,每一行都有p、r和s。
p和s都是Node,r是Relationship。他们都是用neo4j封装好的类来读取。
返回的结果:
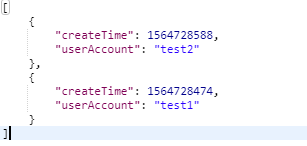
当r有多个时,比如两层的关系时,r就会是一个数组。
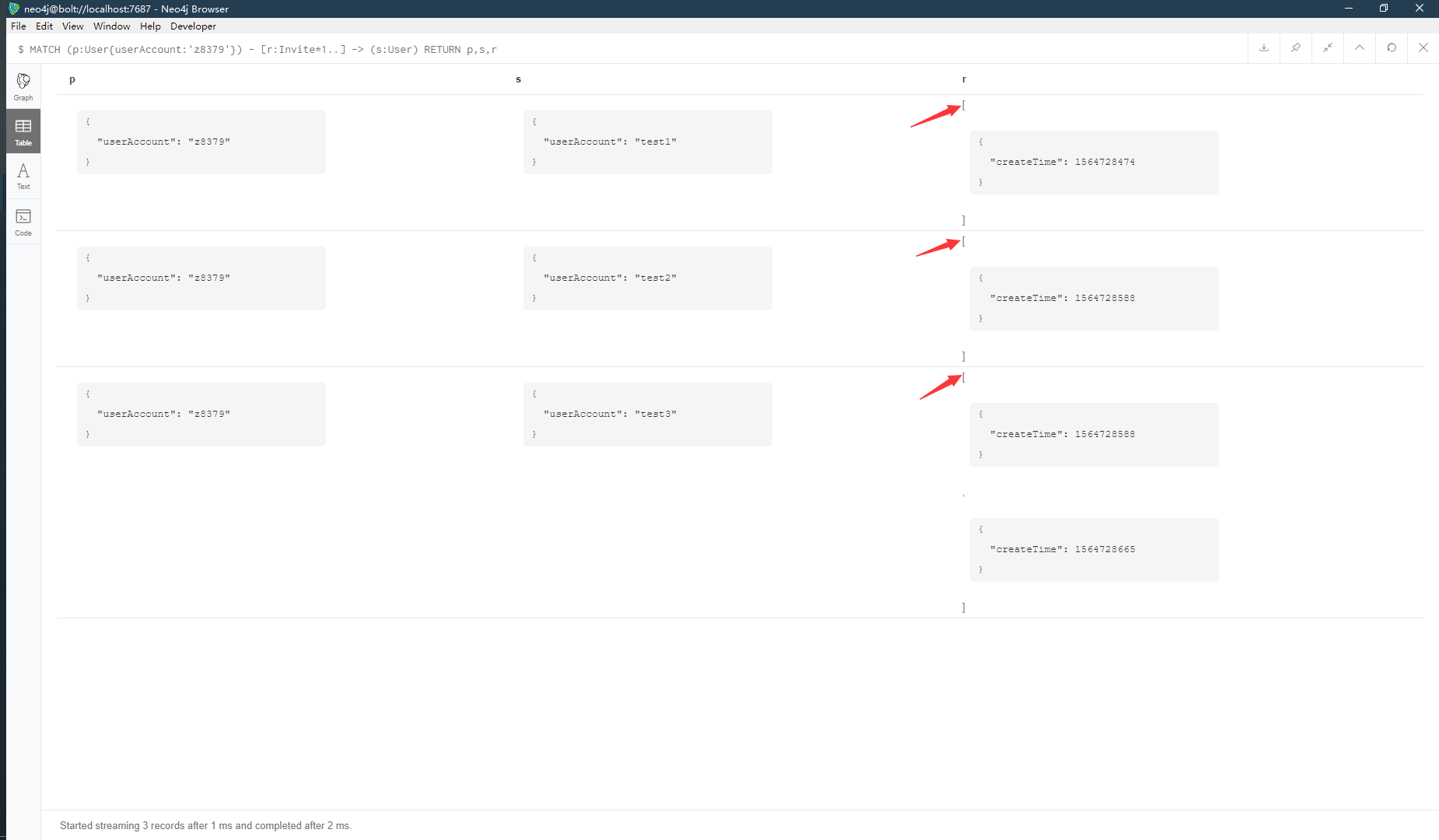
比较头疼的是如果是获取多层级的关系,要想生成树状的json的话,得自己历遍结果集,根据关系数组,写算法生成对应的关系树。
Or you can contact me by Email